
Qual è l’ostacolo per estrarre informazioni dai dati di impianto?
La prima preoccupazione di chi deve ragionare sui dati di impianto è, di solito, capire dove sono e come sia possibile raccoglierli in modo puntuale, affidabile e sicuro.
Ecco allora che si scopre che la maggior parte dei dati di produzione e di impianto sono già disponibili sui PLC e gli SCADA da tempo installati: dati “dormienti”, a volte mai consultati, provenienti da sensori distribuiti sui macchinari e linee di produzione. Serie temporali di dati (time-series, in quanto l’asse delle ascisse del grafico è quasi sempre il tempo), raw-data (dati grezzi), che aspettano solo di essere raccolti e memorizzati in repository (database) appositamente studiati e sviluppati per “storicizzare” tutti i valori dei sensori distribuiti sull’impianto: un Historian!
Ma l’analisi di serie temporali di dati da un impianto di processo a volte non può avvenire in modo efficace finché i dati non vengono puliti da esperti/specialisti che qui chiameremo SME (Subject Matter Expert).
In poche parole, i dati grezzi ci sono ma possono non essere pronti per l’analisi e per ottenere i vantaggi sperati.
Alcune Aziende riferiscono che oltre il 70% del tempo dedicato all’analisi è speso per la pulizia dei dati per portare i dati da grezzi a “dati pronti per l’analisi”. Questi dati vengono generalmente archiviati, a volte nel Cloud, un data lake o in Historian, un repository storico dei processi. (Per inciso, per tutte queste opzioni i costi stanno rapidamente diminuendo, ed anche gli Historian possono risiedere in Cloud).
Contemporaneamente, prezzi più bassi per i sensori (sia cablati che in wireless) stanno creando più dati che mai, che poi vengono instradati ad Historian on-premise o in Cloud.
E questo crea un’immensa opportunità per operatori e supervisori dell’impianto di sfruttare i dati creati dai propri processi e macchinari, dati che possono risultare preziosissimi anche ai fini della Qualità e della Compliance. Ma lascia anche un vuoto, comunemente indicato “data rich, information poor”, ovvero abbiamo tanti dati, ma ci rimangono poche informazioni, perché non riusciamo ad estrarle in modo efficace.
I SME con una conoscenza del processo dovranno quindi ripulire, modellare e contestualizzare i dati prima di iniziare l’analisi.
Inoltre, i Data Scientist a volte non riescono ad eseguire i loro algoritmi finché i dati non sono “pronti”: nonostante tutta la loro esperienza negli algoritmi, i Data Scientist spesso non hanno esperienza di impianto o del processo per sapere cosa possono andare a cercare nei dati.
Ma i SME non sono i custodi di dati, quindi è necessario prima affrontare attività monotone e lunghe in termini di tempo per accesso, pulizia e contestualizzazione dei dati per l’analisi, alla ricerca di soluzioni migliori.
Sono necessarie applicazioni avanzate
Sebbene l’obiettivo dell’analisi sia ottenere informazioni approfondite, ciò deve essere fatto nel contesto dei requisiti di sicurezza dei dati dell’organizzazione. Per questo esistono regole e processi espressi nei protocolli di data governance aziendali per consentire l’accesso ai dati solo da parte di persone autorizzate.
Pertanto, qualsiasi applicazione di analisi avanzata utilizzata per la manipolazione dei dati deve aderire a regole e processi e, quando si raccolgono dati dagli impianti di produzione, è essenziale che i dati di processo rimangano archiviati nella loro forma nativa senza alcuna pulizia o aggregazione. Questo perché anche un piccolo errore di una minima modifica anche di un dato prima di eseguire l’analisi potrebbe avere un impatto negativo o ridurre l’opportunità di approfondimenti futuri.
Pertanto, la trasformazione dei dati da “dati grezzi” a “dati pronti” non dovrebbe avvenire prima dell’archiviazione dei dati da eseguire con un buon Historian.
In seguito i SME possono anche utilizzare fogli di calcolo (come ad esempio MS Excel) per “ripulire i dati”, ma questi strumenti generici spesso non sono adatti a questo compito. Ciò comporta che molti cercano di utilizzare fogli di calcolo per la pulizia e la contestualizzazione dei dati, in un processo lento e manuale.
Le tradizionali applicazioni di BI (business intelligence) sono ottime per i set di dati relazionali, tipiche del mondo IT, ma anche loro non si adattano alla natura dinamica delle serie temporali di dati, tipiche di un Historian utilizzato nell’OT. Ci sono oggi strumenti molto più potenti, agili e facile da usare, come ad esempio proprio Historian.
Historian permette ad esempio di affrontare le questioni fondamentali delle serie temporali di dati, come ad esempio i fusi orari, l’ora legale e i tipi e la logica di interpolazione devono essere impostati dall’utente nelle formule del foglio di calcolo. Fatto semplicemente in Excel, sul proprio desktop potrebbe non essere rilevabile dai colleghi, con la conseguenza che il lavoro deve essere ripetuto più e più volte. Il risultato non sono solo ore spese nell’inferno dei fogli di calcolo per le PMI, ma a volte anche giorni, settimane o mesi.
E questi problemi spingono le aziende a cercare una soluzione migliore sotto forma di applicazioni di analisi avanzate.
Contestualizzare per l’analisi
La contestualizzazione entra in gioco quando i SME preparano i dati per l’analisi attraverso l’integrazione e l’allineamento dei dati da più fonti: si parla di data harmonization, data blending, data fusion, o data augmentation.
In sostanza, i SME si costruiscono un modello, con i differenti tipi di dati, per avere un modello completo dell’asset o del processo combinando anche elementi che arrivano da fonti differenti come ad esempio i dati dai sensori esterni, cosa sta facendo l’impianto o la fase del processo in quel momento e quali parti dei dati possono risultare più importanti per le Operation.
Ed è una sfida crescente in quanto le Aziende di produzione di processo generano sempre più dati: 1 TB/gg (terabyte al giorno) per un impianto medio per arrivare anche a 40 TB/gg per un’azienda con più impianti (vedi Figura 1) – e questo solo per registrare temperature, pressioni, portate, livelli e altri parametri di interesse.
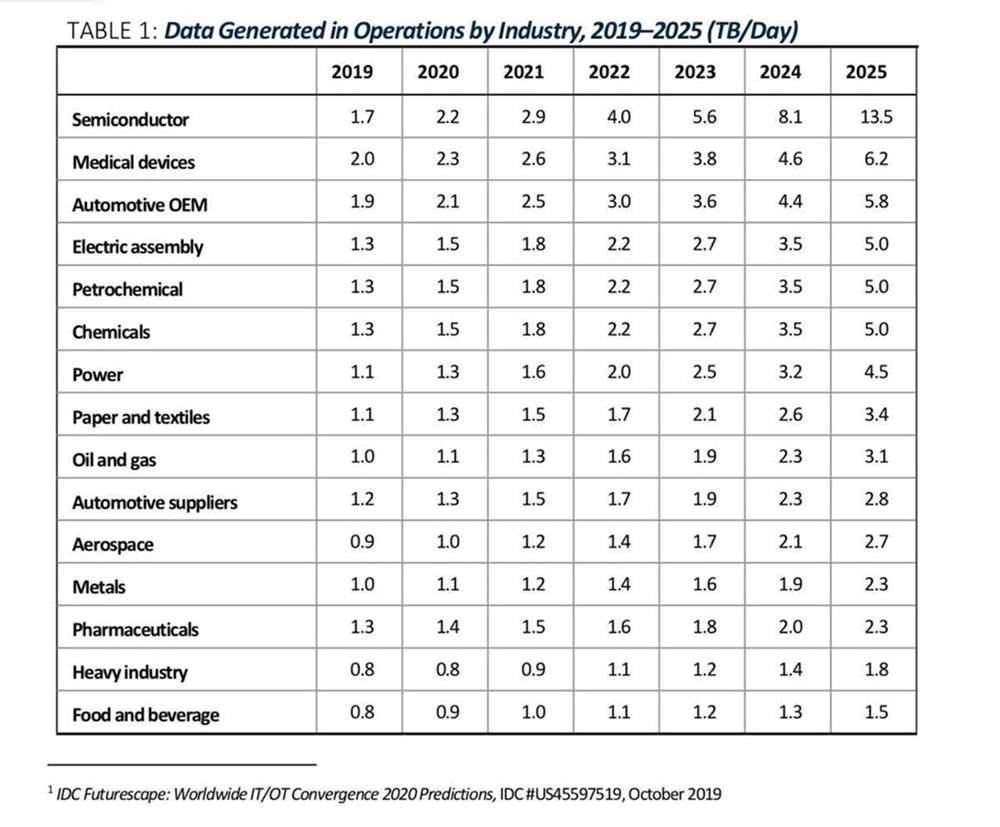
Diamo un’occhiata a un esempio specifico, tipico di quando si lavora con serie temporali di dati di processo.
Un set di dati da un sensore che riporta il valore ogni secondo per un anno si traduce in un totale di 3,1 milioni di punti dati per l’anno, ciascuno sotto la forma timestamp: valore.
Nella maggior parte dei casi non è possibile esaminare tutti questi dati, né può essere necessario.
Infatti, i SME in generale vorrebbero valutare solo specifici intervalli di interesse all’interno di questo insieme annuale di dati.
Qui di seguito sono riportati alcuni esempi di ciò a cui potrebbero essere interessati, con i dati esaminati per l’analisi solo quando le seguenti condizioni sono vere e altrimenti ignorate (vedere la Figura 2):
- Periodo di tempo: per giorno, per turno, mercoledì, giorni feriali vs. fine settimana o altro
- Stato dell’impianto/lena di produzione: acceso, spento, in riscaldamento, fermo o altro
- Un calcolo: periodi di tempo in cui la derivata seconda della media mobile è negativa
- Campioni di dati errati a causa di segnali persi, microfermate, scarti, fuori specifica o altri problemi, ciascuno dei quali richiede la pulizia per migliorare l’accuratezza dell’analisi.
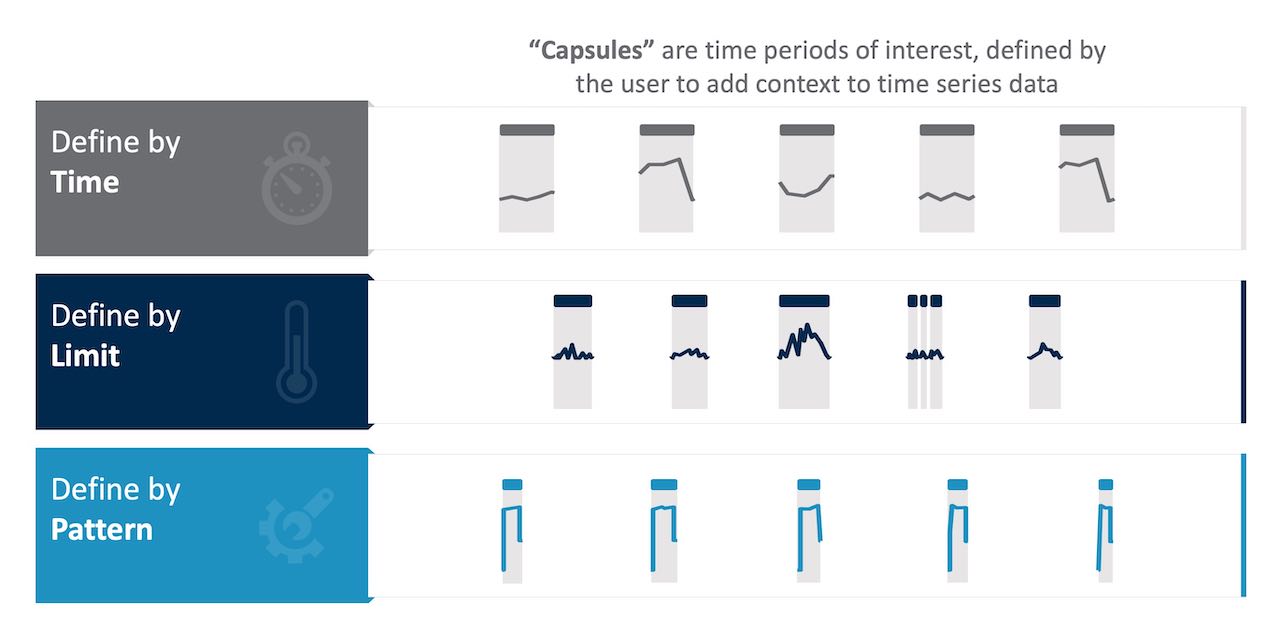
Ciò che è evidente da questo esempio è che anche per un solo anno di dati registrati da un solo segnale, ci sono modi virtualmente illimitati per valutare i dati per l’analisi.
È anche evidente la necessità per i SME di scegliere con saggezza gli intervalli di tempo di interesse quando trasformano i dati per renderli pronti per successive analisi.
Alcuni ambienti di produzione, ad esempio un impianto chimico, possono avere da 20.000 a 70.000 segnali (o sensori), le raffinerie di petrolio possono averne più di 100.000, ed i segnali dei sensori di una multinazionale con diversi impianti possono raggiungere milioni di dati.
La quantità di dati allora può essere enorme, ma perfezionarla e ridurla può sicuramente portare a informazioni più rapide (vedere la Figura 3).

Un altro ostacolo da considerare quando si preparano serie temporali di dati per l’analisi sono l’interpolazione e il calcolo spesso richiesti per l’analisi dei dati, cosa che può essere ignorata dai metodi di aggregazione e consolidamento dei dati IT. Sono infatti necessarie soluzioni specifiche per i dati di produzione, come Historian, perché forniscono la capacità di allineare i segnali con diverse frequenze di campionamento, da diverse fonti di dati, in diversi fusi orari. Queste e altre attività di pulizia dei dati sono senza dubbio necessarie prima di definire i periodi di tempo di interesse da analizzare.
La fase di contestualizzazione
Un modo per espandere i dati operativi raccolti da intervalli di tempo di interesse specifico è contestualizzarli con dati provenienti da altre fonti per migliorare l’impatto sui risultati complessivi.
Quando si combinano diverse origini dati, le domande comuni possono ad esempio essere:
- Qual è il consumo di energia quando si fa il tipo di prodotto 1 rispetto al tipo di prodotto 2?
- Qual è l’impatto della temperatura sulla qualità del prodotto?
- Il consumo di energia cambia al variare del tempo di completamento del batch?
Alcuni esempi di sorgenti di dati comuni includono LIMS (sistemi informativi di laboratorio), MES (sistemi di gestione della produzione), ERP (sistemi di pianificazione delle risorse aziendali), quotazione del prezzo delle materie prime, tariffe delle utenze e altro ancora.
Ecco un esempio di contestualizzazione dei dati richiesta per aggregare e lavorare con dati provenienti da più fonti.
Il risultato è una tabella (Figura 4) di facile comprensione e manipolazione. È anche accessibile ai SME, insieme agli analisti che utilizzano applicazioni di business intelligence come Microsoft Power BI, Tableau, Qlik, ecc.

Guardare all’interno di serie temporali di dati
Le applicazioni di analisi avanzata per serie temporali di dati risultano più semplici da usare, in netto contrasto con gli sforzi analitici richiesti dai fogli di calcolo tradizionali, e ciò consente ai SME di pulire e contestualizzare rapidamente i dati da analizzare.
Con questi tipi di applicazioni, i dati sono accessibili direttamente da Historian o dai silos come richiesto da enti regolatori e non vengono copiati o duplicati, preservando quindi la “Data Integrity” e viene quindi utilizzato per analisi diagnostiche, predittive e analytics in genere.
Le applicazioni di analisi avanzata consentono la collaborazione tra colleghi, attraverso report e dashboard pubblici ed accessibili per approfondimenti a tutte le persone coinvolte nell’Azienda, senza la necessità di sfogliare centinaia o migliaia di righe nei fogli di calcolo. Con le applicazioni di analisi avanzata, è possibile ottenere rapidamente le informazioni che le Aziende possono ottenere estraendo valore dalla serie temporali di dati, rendendo questi dati tanto facili da analizzare quanto raccogliere e archiviare.
Conclusione
C’è oggi molta attenzione sulla trasformazione digitale e come sia possibile utilizzare le informazioni dagli impianti per gestire al meglio i reparti di produzione e le Aziende industriali, e questa attenzione rende più importante che mai comprendere l’importanza di una corretta pulizia dei dati e contestualizzazione delle serie temporali di dati con tutti gli altri dati disponibili da ogni fonte.
Ma ricordiamoci, che alla base di tutte le analisi possibili, c’è la necessità di raccogliere in modo puntuale, affidabile e sicuro i dati dall’impianto, accumulando tutti i valori in repository adeguati, che possano garantire le performance richieste dalle applicazioni di analisi.
Webgrafia:
How raw data is made ready for applying analytics
Seeq.
